Lập Trình Web Scraping Với Crawl4AI và n8n Qua AI
- Sự miêu tả
- Chương trình giảng dạy
- Câu hỏi thường gặp
- Đánh giá
- Cấp
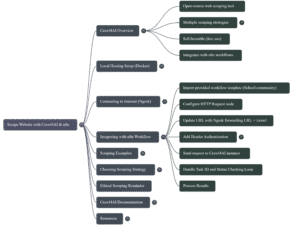
Crawl4AI và Tích hợp với n8n: Tổng Quan về Chiến Lược Thu Thập Dữ liệu
Crawl4AI là một công cụ web scraping mã nguồn mở mạnh mẽ, sử dụng nhiều chiến lược khác nhau, bao gồm cả chiến lược dựa trên Trí tuệ Nhân tạo (AI). Việc tích hợp Crawl4AI vào nền tảng tự động hóa n8n được thực hiện thông qua các yêu cầu HTTP, khi Crawl4AI được host cục bộ (thường qua Docker) và kết nối qua proxy như Ngrok.
I. Các Chiến lược Thu thập Dữ liệu (Extraction Strategies)
Crawl4AI hỗ trợ nhiều loại cấu hình trích xuất (extraction config) khác nhau, được truyền trong phần thân yêu cầu HTTP gửi đến Crawl4AI.
1. Chiến lược Cơ bản (Basic Extraction)
- Mục đích: Trích xuất toàn bộ nội dung HTML từ một hoặc nhiều URL.
- Cấu hình: Đặt
typelàbasictrong extraction config. - Đầu ra: Kết quả bao gồm toàn bộ HTML và nội dung dưới dạng markdown. Ví dụ, có thể dùng để scrape toàn bộ trang web tài liệu và chuyển đổi sang markdown.
- Sử dụng trong n8n: Trong yêu cầu HTTP, trường
URLschứa mảng các chuỗi URL cần thu thập.
2. Chiến lược dựa trên LLM/AI (LLM/AI Extraction)
- Mục đích: Sử dụng Mô hình Ngôn ngữ Lớn (LLM) để phân tích trang web và trích xuất dữ liệu có cấu trúc từ nội dung không có cấu trúc, giữ lại chỉ thông tin cần thiết.
- Cấu hình: Đặt
typelàLLM. - Chi tiết cấu hình:
- LLM Config: Chọn nhà cung cấp LLM như OpenAI GPT-4 mini, Gemini, Claude… Crawl4AI tích hợp qua LightLLM để kết nối các nhà cung cấp này.
- Schema: Xác định cấu trúc đầu ra mong muốn, ví dụ tên mô hình, phí đầu vào, phí đầu ra.
- Instruction (Hướng dẫn): Cung cấp chỉ dẫn cho AI về nội dung cần trích xuất từ dữ liệu đã crawl.
- Extraction Type: Thường đặt là
schemađể đảm bảo đầu ra theo cấu trúc định nghĩa.
- Thời điểm sử dụng: Khi cấu trúc trang web không đoán trước hoặc không đồng nhất, ví dụ như bài báo chứa khối văn bản lớn cần trích xuất thông tin cụ thể.
3. Chiến lược dựa trên CSS (JSON CSS Structured Scraper)
- Mục đích: Trích xuất dữ liệu nhắm mục tiêu các phần tử HTML qua bộ chọn CSS (CSS selector).
- Cấu hình: Đặt
typelàJSON CSS. - Chi tiết cấu hình:
- Base Selector: Xác định phần tử HTML cơ sở, ví dụ
div.product-card, để công cụ crawl tập trung trích xuất. - Field Selectors: Định nghĩa các trường dữ liệu cần lấy tương ứng với các selector con bên trong phần tử cơ sở.
- Base Selector: Xác định phần tử HTML cơ sở, ví dụ
- Lợi ích: Hiệu quả khi trích xuất dữ liệu có cấu trúc rõ ràng từ các trang web thương mại điện tử, danh sách sản phẩm, bảng giá,…
II. Tích hợp Crawl4AI vào Workflow n8n
Để tích hợp Crawl4AI vào hệ thống tự động hóa n8n, bạn thực hiện các bước sau:
- Host Crawl4AI cục bộ bằng Docker.
- Kết nối qua proxy như Ngrok để mở cổng truy cập từ xa.
- Tạo node HTTP Request trong n8n để gửi yêu cầu đến Crawl4AI với đúng extraction config tùy thuộc chiến lược được chọn (Basic, LLM, hoặc JSON CSS).
- Xử lý kết quả trả về trong workflow n8n để lưu trữ, phân tích hoặc tiếp tục luồng công việc.
Việc này giúp tự động hóa quá trình thu thập và xử lý dữ liệu web phức tạp một cách linh hoạt, đặc biệt khi kết hợp khả năng AI nâng cao của Crawl4AI.
III. Kết luận
Crawl4AI với ba chiến lược thu thập dữ liệu chính: Basic, LLM/AI, và JSON CSS cho phép thu thập dữ liệu đa dạng và linh hoạt. Khi tích hợp với n8n, nó tạo thành một giải pháp tự động hóa mạnh mẽ phục vụ các nhu cầu scraping từ đơn giản đến phức tạp, đặc biệt là khi dữ liệu có cấu trúc hoặc phi cấu trúc đòi hỏi phân tích thông minh.
-
1
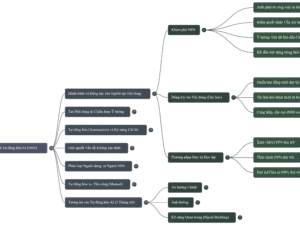
 Tổng quan về Crawl4AI và n8n
Tổng quan về Crawl4AI và n8nChủ đề chính:
- Cạo web miễn phí với Crawl4AI: Điểm nhấn chính là khả năng tự lưu trữ Crawl4AI và sử dụng nó mà không phải trả phí.
- Chiến lược cạo web đa dạng: Crawl4AI hỗ trợ nhiều chiến lược cạo, bao gồm cạo cơ bản, cạo dựa trên AI và cạo dựa trên bộ chọn CSS JSON.
- Tích hợp với n8n: Sử dụng n8n làm nền tảng không mã (no-code) để xây dựng và quản lý các quy trình cạo web.
- Thiết lập và triển khai cục bộ: Hướng dẫn chi tiết về cách thiết lập Crawl4AI cục bộ bằng Docker và kết nối nó với internet bằng Enrok.
- Tầm quan trọng của cạo web có đạo đức: Lời nhắc nhở về việc cạo web có trách nhiệm.
-
2
 Cài đặt Crawl4AI trên Docker và cấu hình proxy với Ngrok
Cài đặt Crawl4AI trên Docker và cấu hình proxy với Ngrok -
3
 Thiết lập kết nối HTTP giữa n8n và Crawl4AI
Thiết lập kết nối HTTP giữa n8n và Crawl4AI -
4
 Bài tập thực hành: Triển khai và kết nối Crawl4AI với n8n qua proxy
Bài tập thực hành: Triển khai và kết nối Crawl4AI với n8n qua proxy
- Tên khóa học: Ứng dụng Crawl4AI trong Web Scraping và Tự động hóa với n8n
- Thời lượng: 4 tuần
- Hình thức: Trực tuyến, học qua video và thực hành
- Ngôn ngữ: Tiếng Việt
- Mức độ: Trung cấp đến nâng cao
- Hiểu biết cơ bản về web scraping và HTTP requests
- Kiến thức cơ bản về Docker và hosting cục bộ
- Nắm vững khái niệm proxy và cách sử dụng trong mạng (ví dụ: Ngrok)
- Hiểu biết sơ lược về mô hình ngôn ngữ lớn (LLM) và AI
- Kỹ năng sử dụng công cụ n8n để thiết lập workflow tự động
- Nhà phát triển web và lập trình viên muốn tự động hóa việc thu thập dữ liệu
- Chuyên viên phân tích dữ liệu cần thu thập dữ liệu chất lượng cao từ web
- Người làm việc với AI và muốn tích hợp web scraping thông minh vào quy trình làm việc
- Học viên và sinh viên ngành công nghệ thông tin, trí tuệ nhân tạo
- Người quản lý dự án liên quan đến tự động hóa và thu thập dữ liệu
